Latency: from linear growth to exponential decay with number of backends
We’ve already discussed how do we measure latency and that we use p95, p99, and sometimes p999.
Let’s look at what happens when we have multiple backends. For simplicity, I’m going to use the same latency profile for all backends.
And you can think of these backends as redises.
Sequential access is not great.
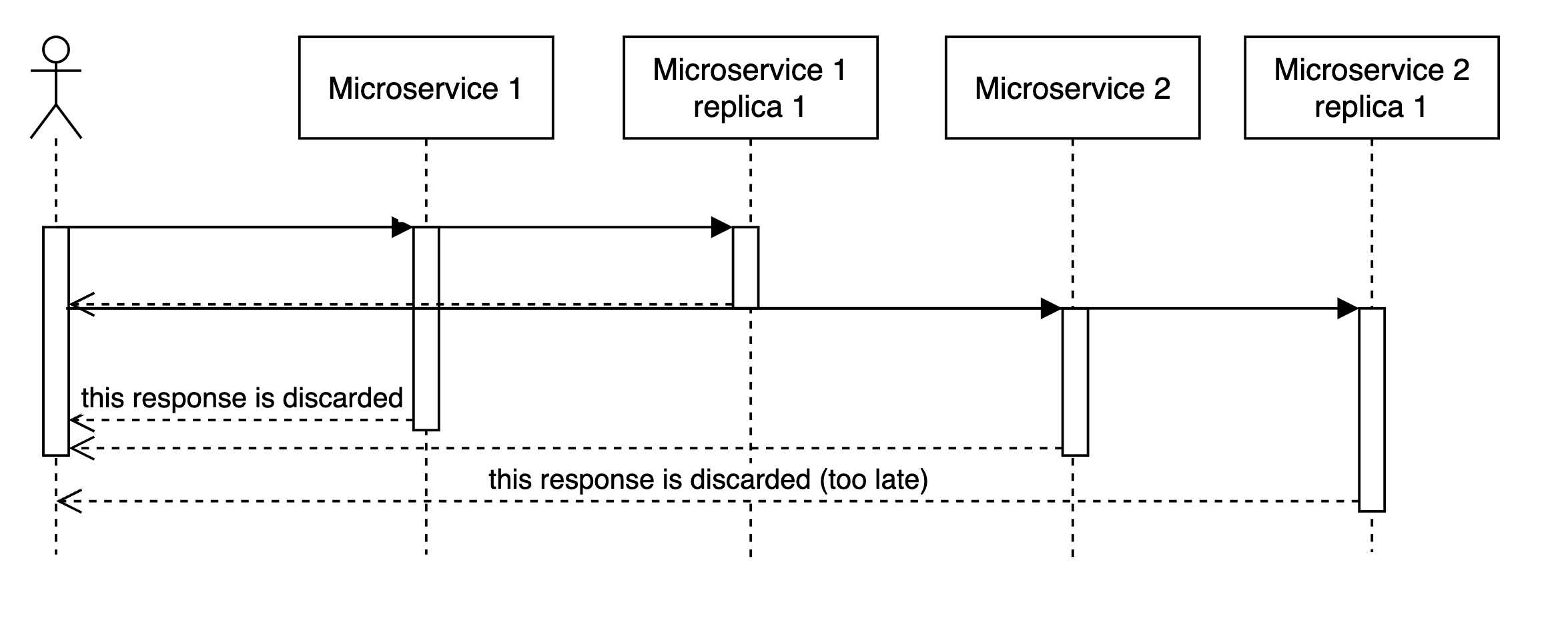
Imagine that when request comes we handle it like this:
- Some logic
- Access microservice
- Some extra logic … N. response
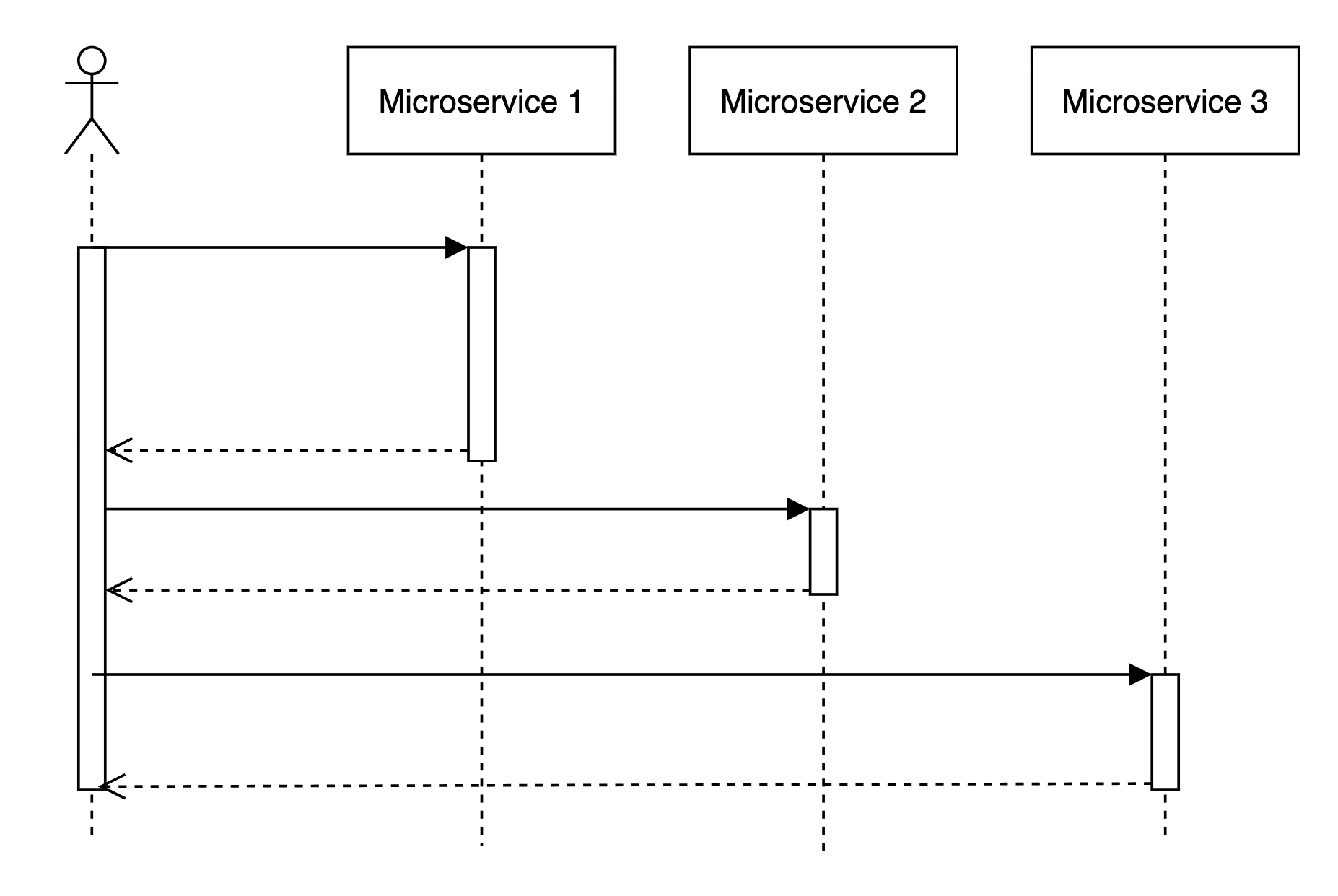
In this case, tail latencies will stack up in an expected linear manner.
Can we do anything about it?
Yes, we can! If we can refactor our app to make parallel calls to all downstream microservices in parallel, our IO latency would be capped by the slowest response of a single service!
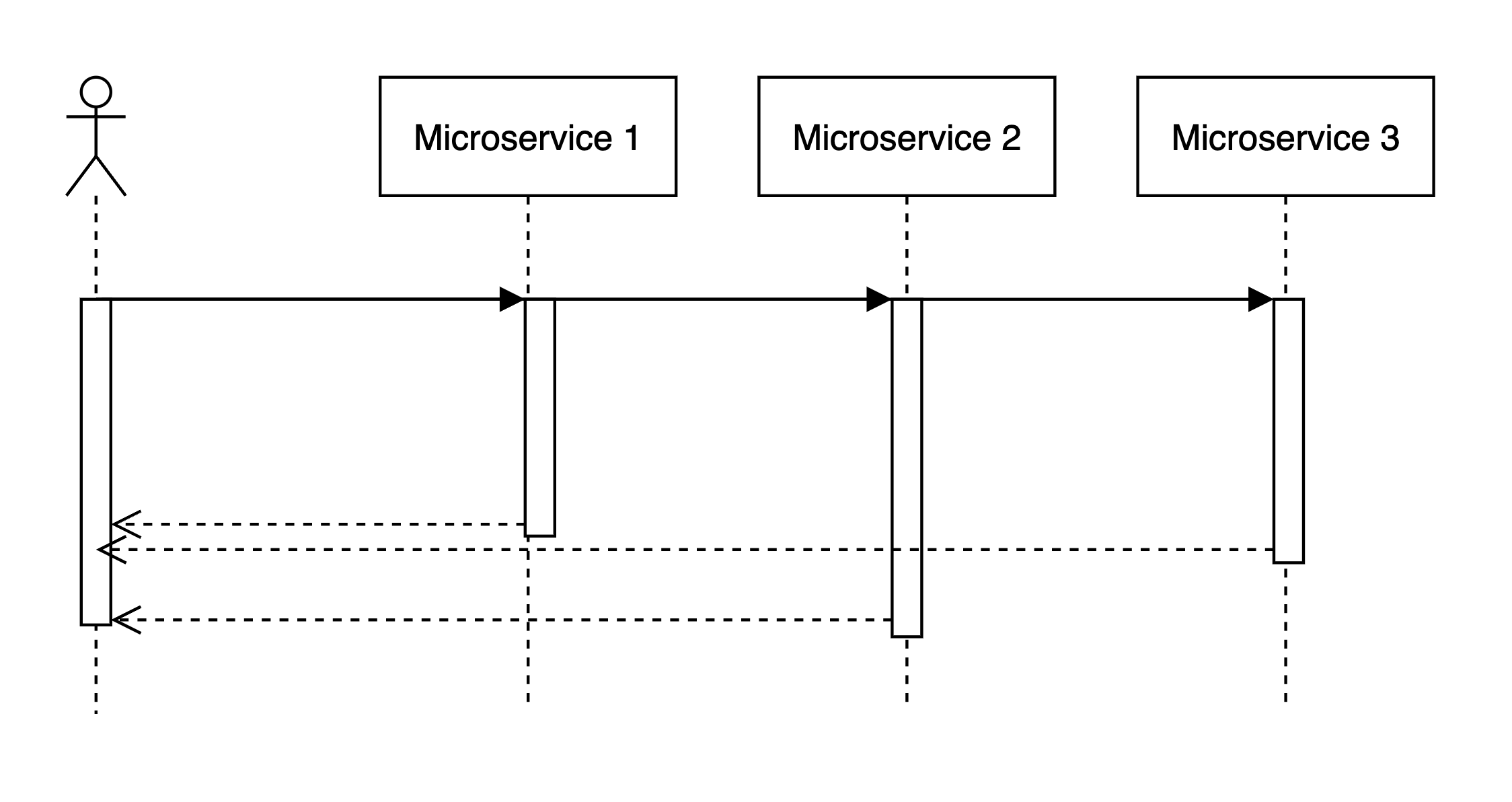
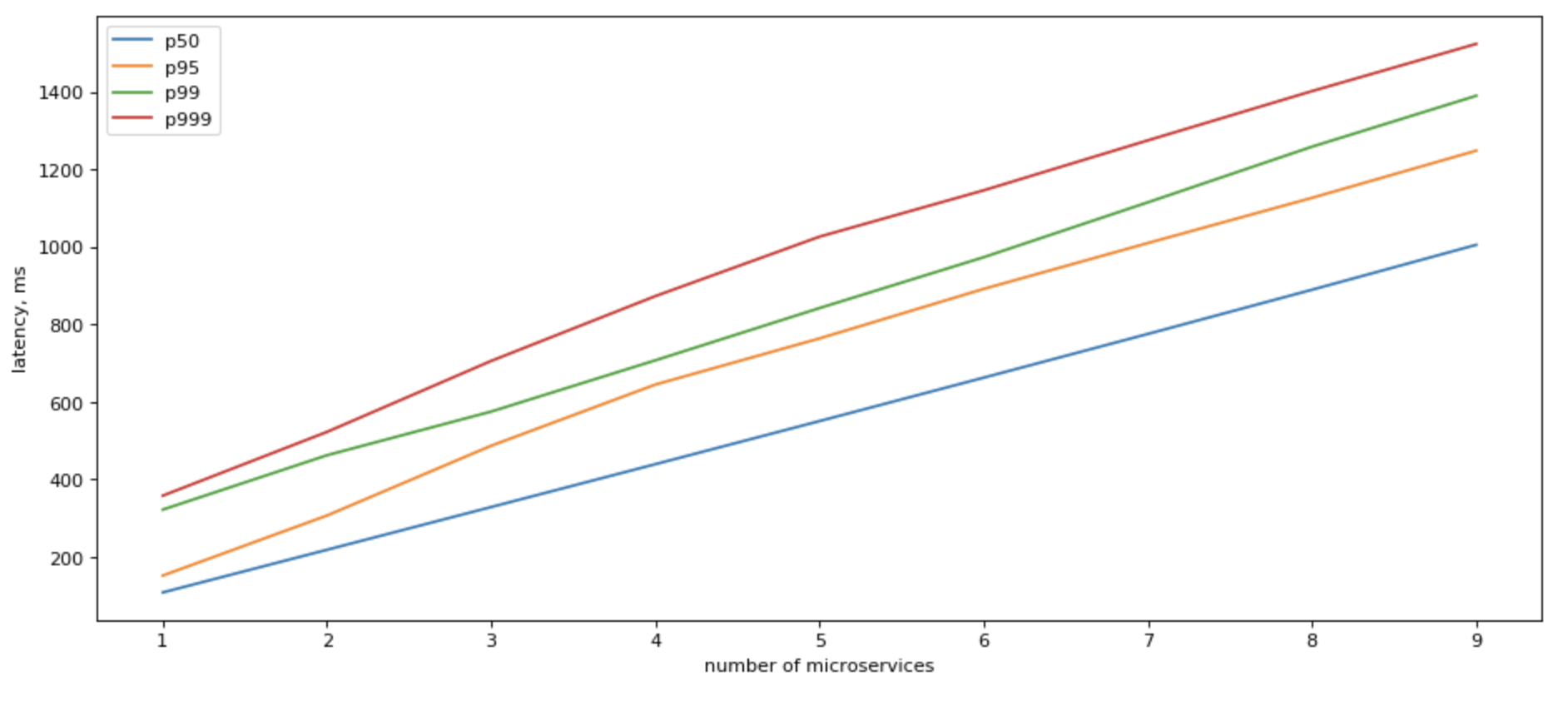
In that case, tail latency would grow roughly logarithmically with the number of backends:
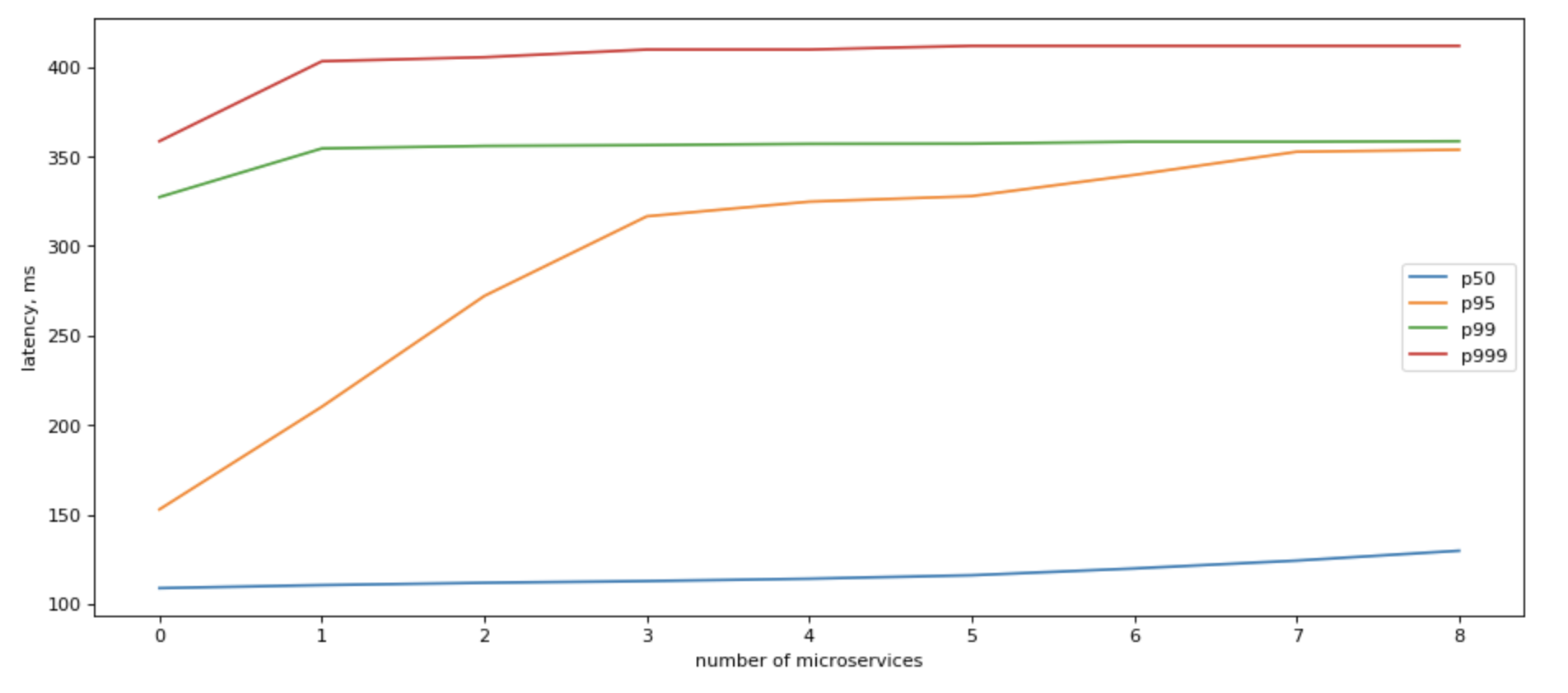
If we look at what sequential IO gives us, the picture becomes clearer:
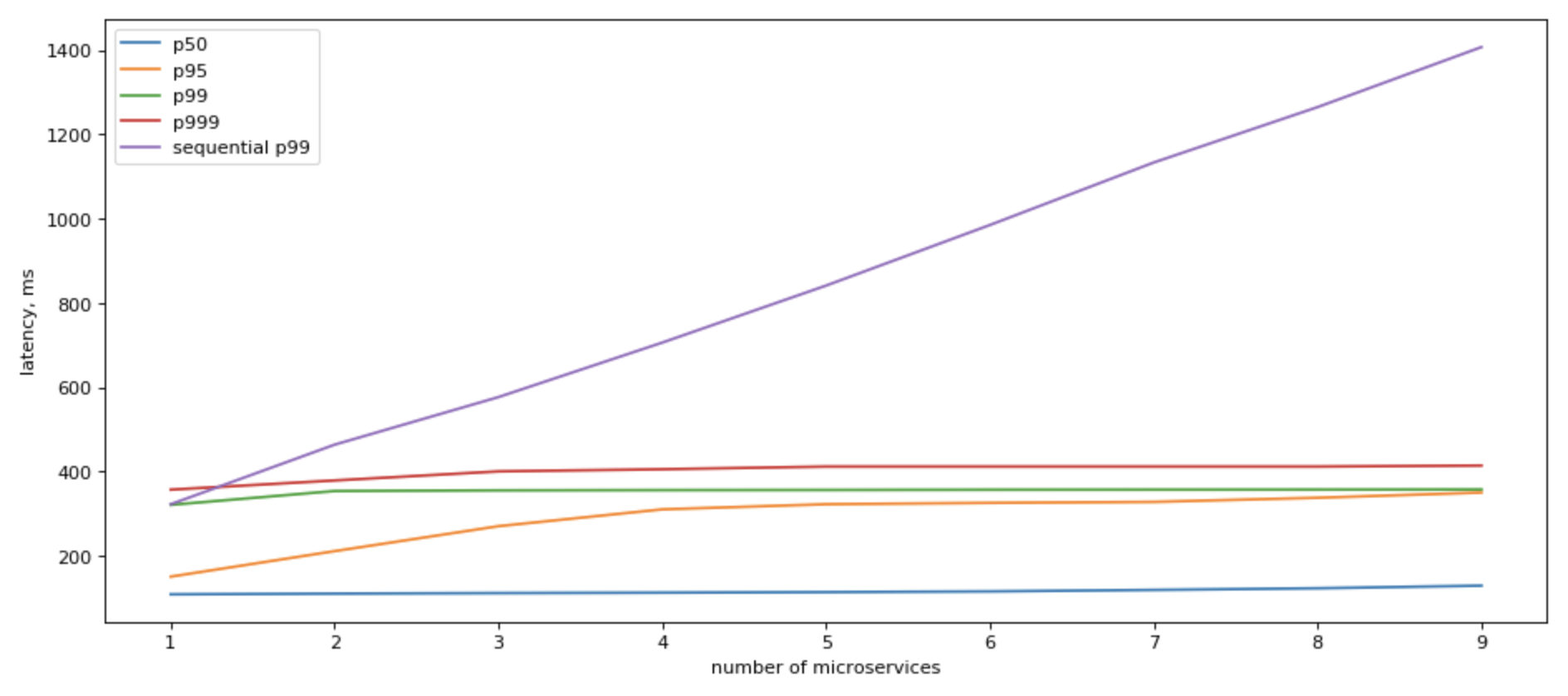
It still slower than having just 1 microservice to access, but it’s a very significant positive change.
Can we do something more about it?
Parallel microservices access
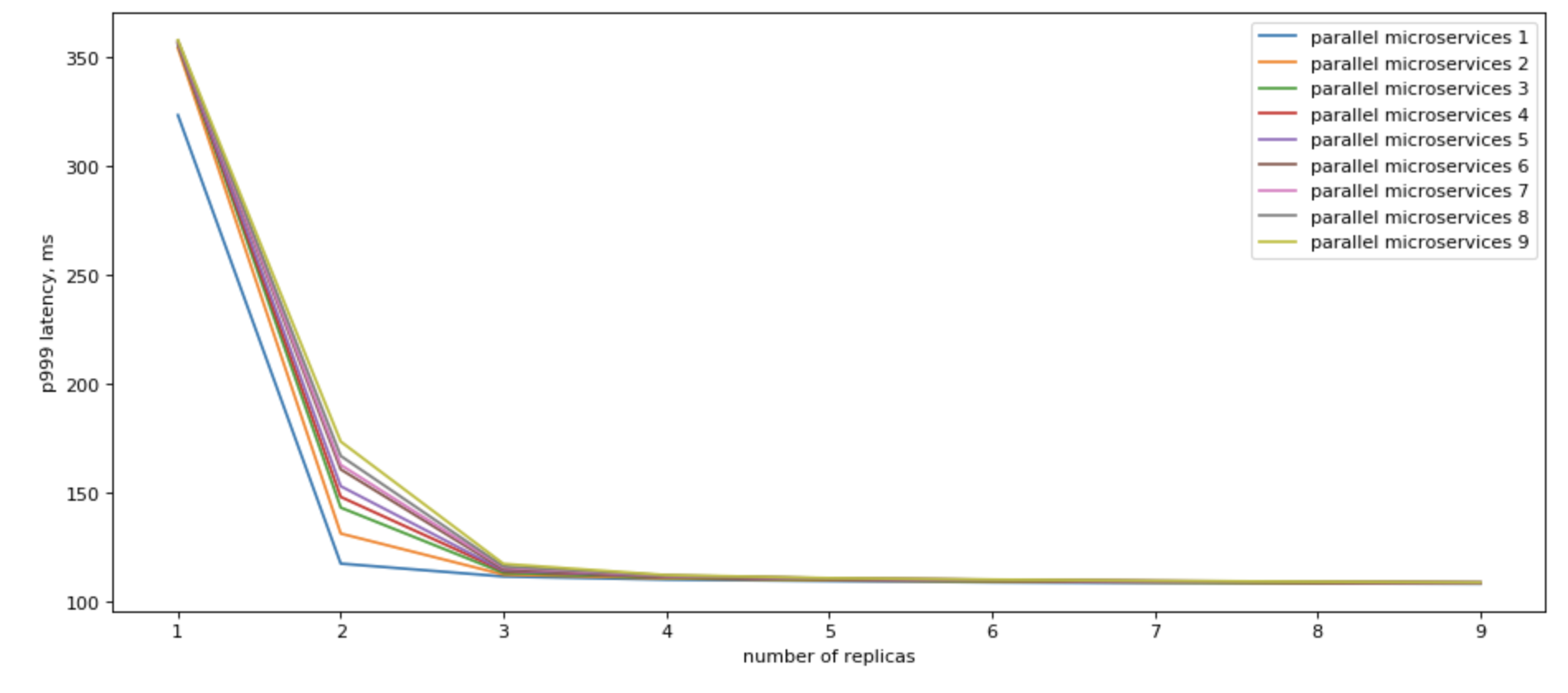
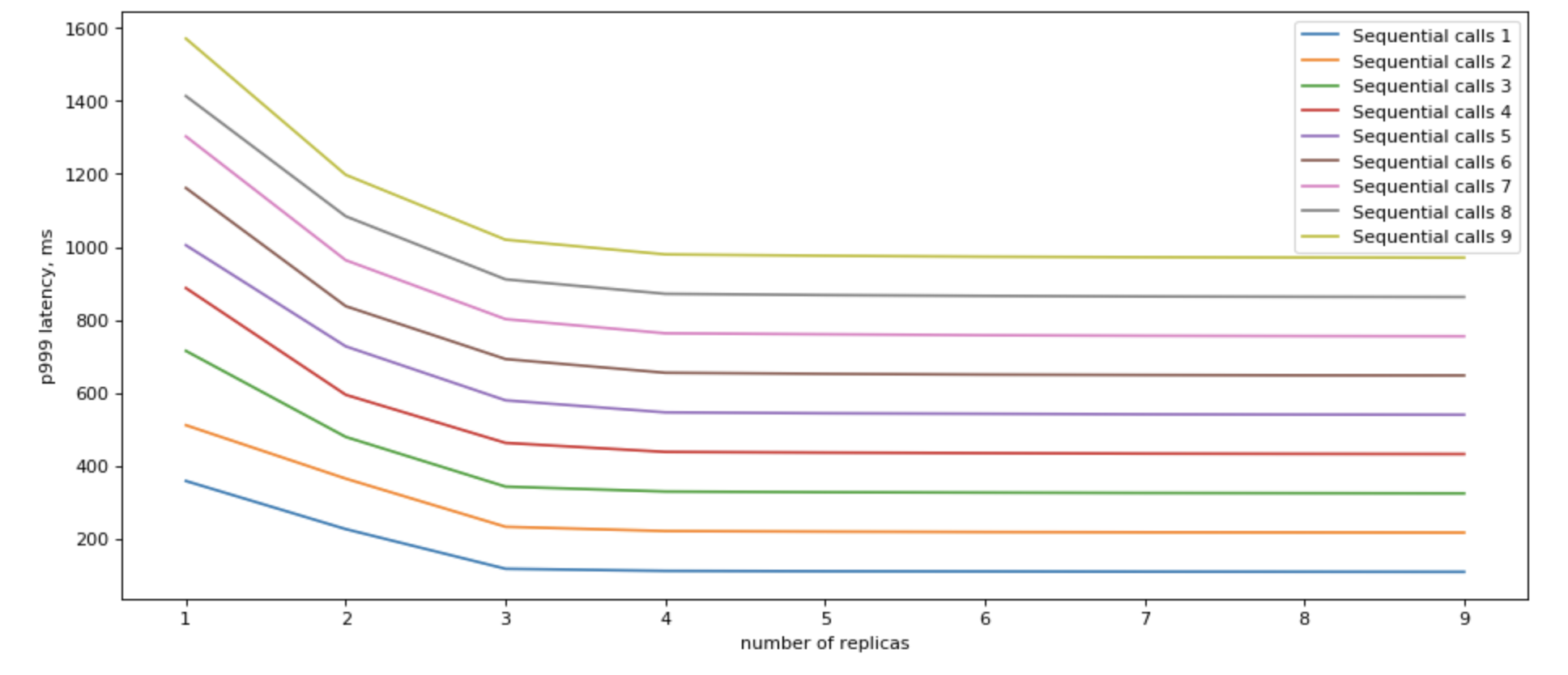
Yes, we can! If we can use multiple replicas, we can do parallel calls to all of them, and when we recieve the fastest answer, cancel all other in-flight requests, we would have a vey nice p99
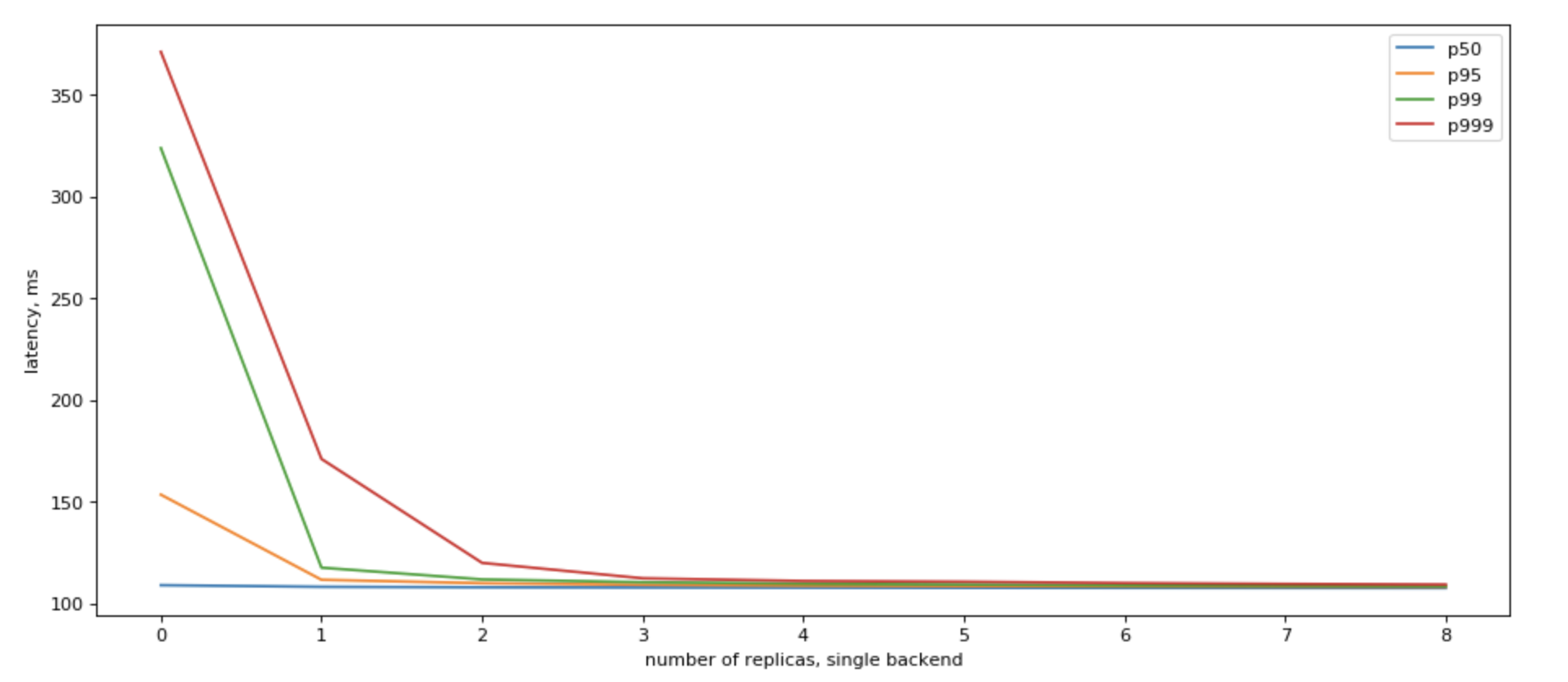
Please also note, that we get the most results by having just a few (3) read replicas.
Improving sequential microservices access
So for cases when we can’t change the sequetial matter of our code, we can add read replicas, and expect some imporovement, if we send requests to all read replicas in parallel, and as soon as we get first one (i.e. the fastest one), we go on.
In general, looks like for practical purposes and a single backend, it does quite well at 2 read replicas.
But it’s not great.
Improving parallel microservices access
If you call multiple read replicas in parallel, you would get a remarkable improvement in terms of latency.
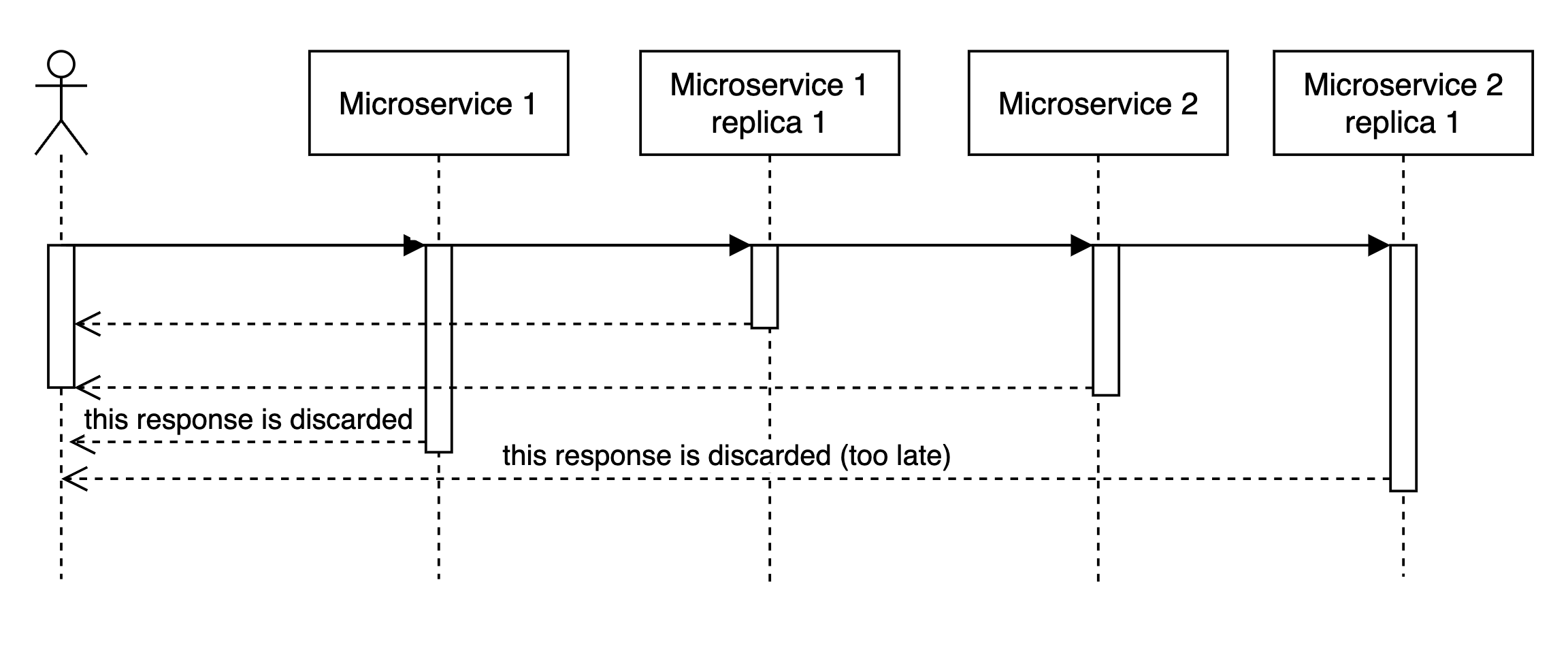
There are a few points to consider:
- We are already fast with parallel calls. Do we need to be faster? Is it worth it?
- We likely have replicas for fault tolerance. Can we use them as read-only replicas?
- Network overhead. If you are close to network stack saturation on your nodes, does it make sense to double or triple the load?